
Managed instances
This documentation details how the Distribution team at Sourcegraph internally handles the provisioning/creation/configuration/maintenance of managed instances.
Please first read the customer-facing managed instance documentation to understand what these are and what we provide.
- Technical details
- Cost estimation
- Requesting a managed instance
- Creating a managed instance
- Managed instances operations
- Upgrading a managed instance
- FAQ
Requesting a managed instance
After determining a managed instance is what a customer/prospect wants, Customer Engineers should:
- Submit a request to the Delivery team via the Managed Instance Request issue template in the sourcegraph/customer repo
- Add the issue to the ”Delivery” board in GitHub (leave the status blank)
- Message the team in #delivery
Technical details
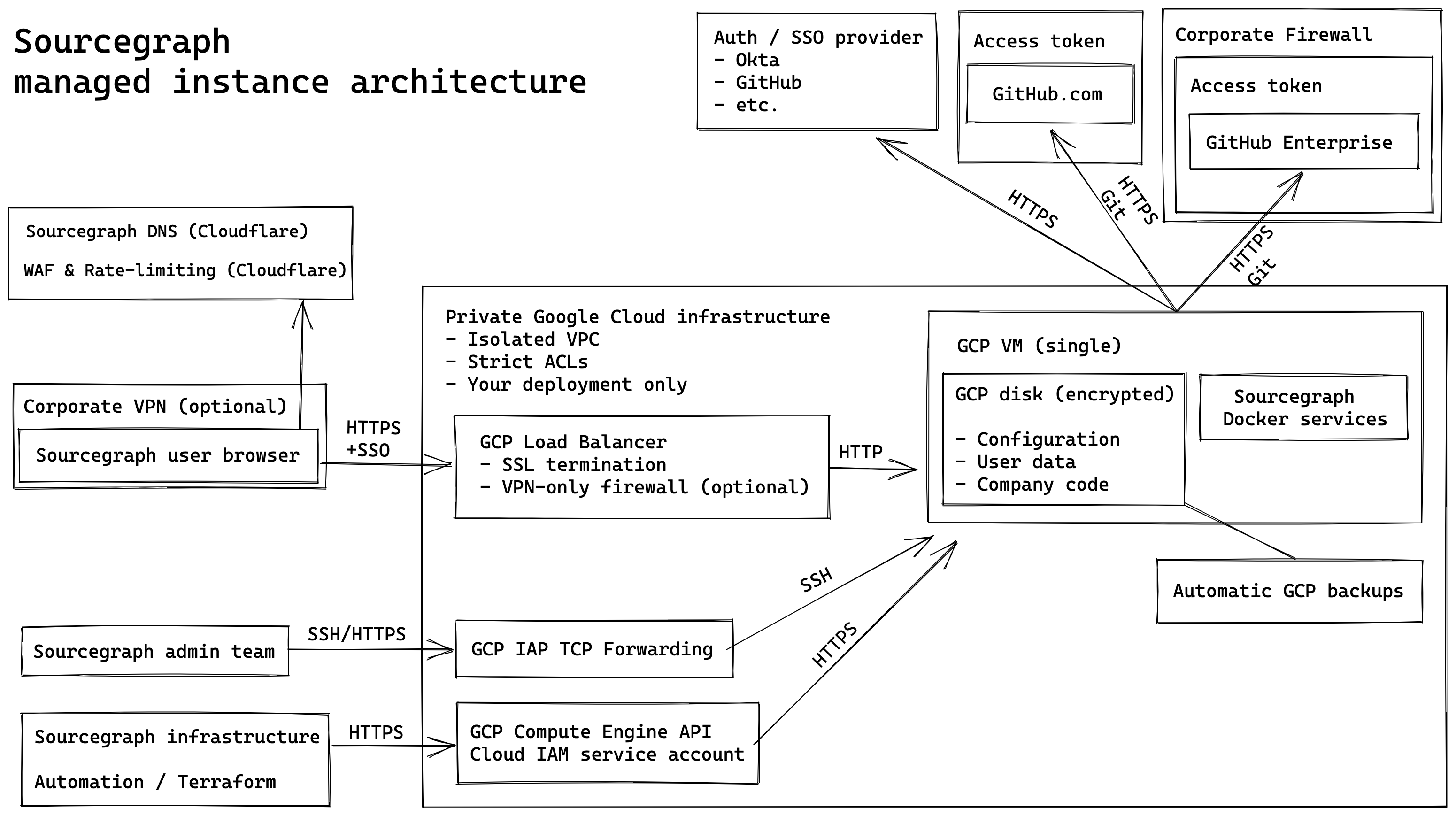
Deployment type and scaling
Managed instances are Docker Compose deployments only today. We do not currently offer Kubernetes managed instances.
These managed Docker Compose deployments can scale up to the largest GCP instance type available, n1-standard-96 with 96 CPU / 360 GB memory which is typically enough for most medium to large enterprises.
We do not offer Kubernetes managed instances today as this introduces some complexity for us in terms of ongoing maintenance and overhead, we may revisit this decision in the future.
Known limitations of managed instances
Sourcegraph managed instances are single-machine Docker-Compose deployments only. We do not offer Kubernetes managed instances, or multi-machine deployments, today.
With that said, Docker Compose deployments can scale up to the largest GCP instance type available, n1-standard-96 with 96 CPU & 360 GB memory, and are typically capable of supporting all but the largest of enterprises (around 25,000 repositories and 3,000 users are supported, based on what we have seen thus far.)
The main limitation of this model is that an underlying GCP infrastructure outage could result in downtime, i.e. is it not a HA deployment.
See also: Dev FAQ: Why did we choose Docker Compose over Kubernetes deployments?
Security
- Isolation: Each managed instance is created in an isolated GCP project with heavy gcloud access ACLs and network ACLs for security reasons.
- Admin access: Both the customer and Sourcegraph personnel will have access to an application-level admin account.
- VM/SSH access: Only Sourcegraph personnel will have access to the actual GCP VM, this is done securely through GCP IAP TCP proxy access only. Sourcegraph personnel can make changes or provide data from the VM upon request by the customer.
- Inbound network access: The customer may choose between having the deployment be accessible via the public internet and protected by their SSO provider, or for additional security have the deployment restricted to an allowlist of IP addresses only (such as their corporate VPN, etc.)
- Outbound network access: The Sourcegraph deployment will have unfettered egress TCP/ICMP access, and customers will need to allow the Sourcegraph deployment to contact their code host. This can be done by having their code-host be publicly accessible, or by allowing the static IP of the Sourcegraph deployment to access their code host.
Access
- To perform the steps outlined in these docs you will need to be a member of:
- The google group gcp-managed
- 1Password Vaults
Customer managed instances&Internal managed instances
Access can be requested in #it-tech-ops WITH manager approval.
Configuration management
Terraform is used to maintain all managed instances. You can find this configuration here: https://github.com/sourcegraph/deploy-sourcegraph-managed
All customer credentials, secrets, site configuration, app and user configuration—is stored in Postgres only (i.e. on the encrypted GCP disk). This allows customers to enter their access tokens, secrets, etc. directly into the app through the web UI without transferring them to us elsewhere.
FAQ
FAQ: Can customers disable the “Builtin username-password authentication”?
No, this is required in order for Sourcegraph to access the instance and debug issues through the initial admin account.
However, it does not need to be used by the customer or their users at all. The default login method can be configured to their SSO provider of choice.
FAQ: Why did we choose Docker Compose over Kubernetes deployments?
Managed instances is an interim solution to having the Sourcegraph.com Cloud natively support multi-tenant private repositories. The thinking has been that:
- Managed instances are a good interim solution because Sourcegraph.com Cloud native support for private repositories is several quarters out, at least.
- Managed instances are something we can not invest in at all until we see customer traction, and we can tailor how much we invest based on customer traction.
- Managed instances are something with little ongoing maintenance burden to us as long as we keep them simple, and automate as much as possible when we begin to see traction.
Because of these reasons, and due to this being an interrupt to our regularly scheduled work, a few things with Kubernetes managed instances did not make sense at our current point in time:
- We would need to set up multi-machine backup infrastructure and processes for restoration—substantially harder to do on a moments notice.
- Managing network ACLs in a Kubernetes deployment was substantially harder to do:
- Need static NAT IPs for prospective customers to allow access to their code host which may be behind a corporate firewall.
- Need to integrate something like GCP load balancer for SSL termination with IP allow-listing (to restrict access to customer’s VPN only)
- Performing upgrades in Kubernetes deployments is substantially more time consuming:
- Being confident about addressing merge conflicts on upgrades and having them not result in unwanted changes has been difficult for us and customers.
- We do not have proper automation in place for Kubernetes upgrades, and automating Docker Compose upgrades seemed much more straightforward.
Additionally, we noted the following:
- Docker-Compose deployments have suited companies up to 25k repos & ~3000 devs well in the past (and, frankly, beyond that..)
- We have a proper production Kubernetes deployment (sourcegraph.com) but lacked a proper Docker-Compose production deployment—this could act as that and ensure we do even more proper diligence with that deployment type and keep it functioning well for the many customers out there running it today.
- For the first customer requesting managed instances, we had a spin-up time of approx ~3d only.
None of this is to say that we will not consider switching said managed instances to Kubernetes in the future under different circumstances—it is just to say we are not doing that today.
FAQ: “googleapi: Error 400: The network_endpoint_group resource … is already being used”
If terraform apply is giving you:
Error: Error when reading or editing NetworkEndpointGroup: googleapi: Error 400: The network_endpoint_group resource 'projects/sourcegraph-managed-$COMPANY/zones/us-central1-f/networkEndpointGroups/default-neg' is already being used by 'projects/sourcegraph-managed-$COMPANY/global/backendServices/default-backend-service', resourceInUseByAnotherResource
Or similar—this indicates a bug in Terraform where GCP requires an associated resource to be deleted first and Terraform is trying to delete (or create) that resource in the wrong order.
To workaround the issue, locate the resource in GCP yourself and delete it manually and then terraform apply again.